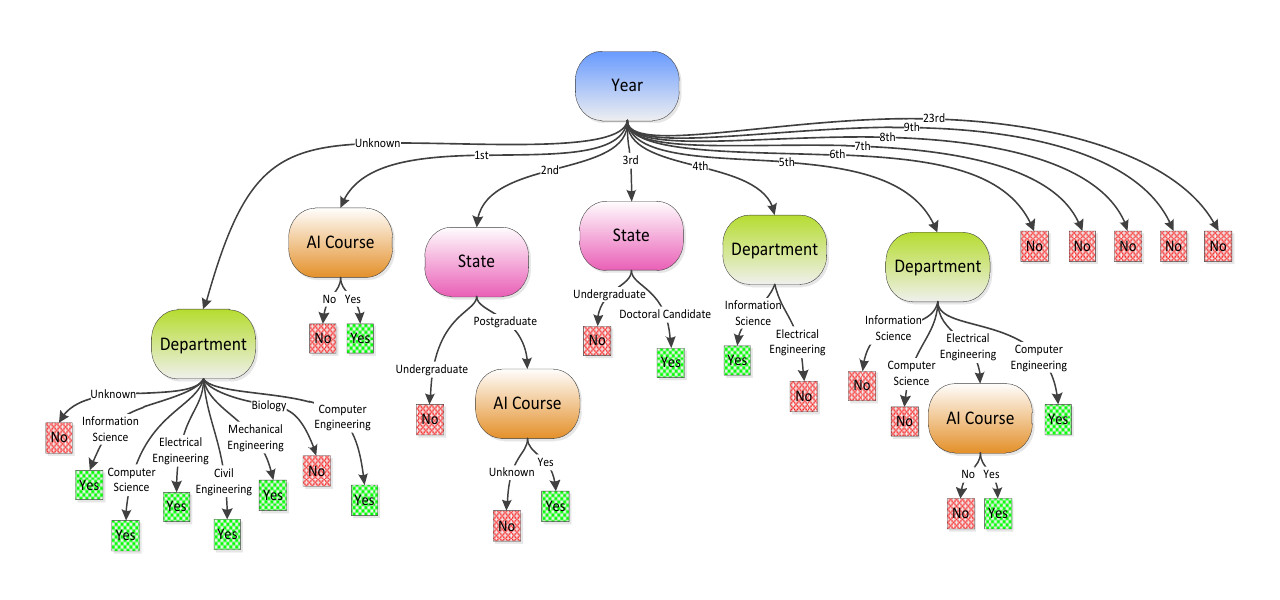
This is a lab assignment in the “Artificial Intelligence II” course of the ECE department at the University of Patras, for the academic year 2011 - 2012. It involves building a decision tree on a dataset about the process of providing scholarships for a certain number of attendees to the Hellenic Artificial Intelligence Summer School (HAISS) 2011.
The provided dataset is a spreadsheet with the following attributes:
| Academic Level | Has Attended AI Course | Year of Study | Department | University | Scholarship |
The entries have values like:
| Undergraduate | Yes | 4th | ECE | UPatras | No |
The first thing I had to do was to encode the data so they can be handled by the algorithm. The scheme was to assign a unique zero based index to each of the different categories within each attribute:
| 1 | 1 | 4 | 3 | 5 | 0 |
In the implementation, decision_tree_learning is the main function of the algorithm. It takes the following parameters: examples - remaining training set on the current node, depth - depth of the current node, attributes - remaining attributes (labels) on the current node, tree_path - path from the root to the current node, parent_examples - remaining training set on the parent node of the current node.
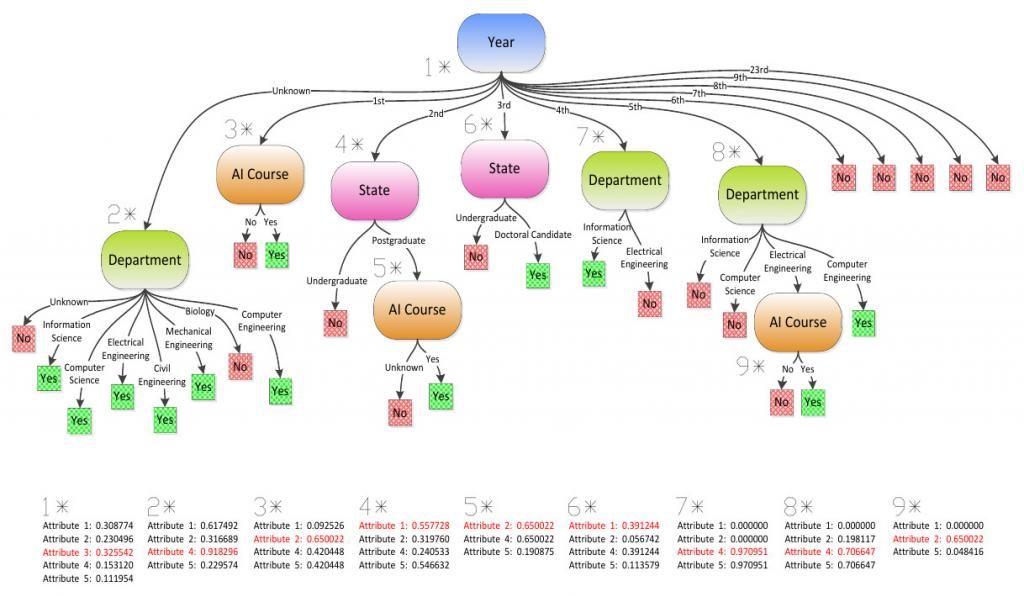
decision_tree_learning(examples, depth, attributes, tree_path, parent_examples)The encoded dataset appears on the HAISS2011.txt file. It is loaded automatically, and the resulting decision tree is displayed dynamically on the terminal. The algorithm creates the nodes on the tree in a depth first traversal. When a new node is created, we get back information (information gains of all remaining attributes) about the decision to peek the current attribute. For every leaf node that’s created, the path to that node and the outcome is displayed on the console.
% Sample output (node 5 on the figure)
Depth 2:
=============
Information Gains:
Attribute 2: 0.650022
Attribute 4: 0.650022
Attribute 5: 0.190875
Attribute with the highest I.G.: 2
Path:
==========
Attribute: 3 1 2
Value : 2 2 0
Output : 0
Path:
==========
Attribute: 3 1 2
Value : 2 2 2
Output : 1The source code is available on GitHub.