It’s been three years since my last post. And with just two posts in the record, you wouldn’t say I have much of a blog. I’ve been wanting for a long time to share some content about the things I do every day, but as with everything else in life, you need motivation to help you set your priorities straight.
ROS has been in the center of my attention for the last two years. It is a great tool to help you accelerate the development of your robotics projects. ROS has been growing along with its community, so it continuously gets updated and extended to accommodate its needs. As a result of this adaptation, there are certain parts of ROS that have been taken care of and work great under all circumstances, and others that have been left more or less untouched for the sake of compatibility or else, and this sucks. I didn’t get the chance to document my ROS experiences before, but I will make an effort to do that now… and I will start with ROS diagnostics.
There is a lot of documentation on ROS diagnostics, but, at least to me, it seems unnecessarily complicated. So I thought I try to explain it in a few and simple words, and focus on what ROS diagnostics is today, and not what it can be. That will come later.
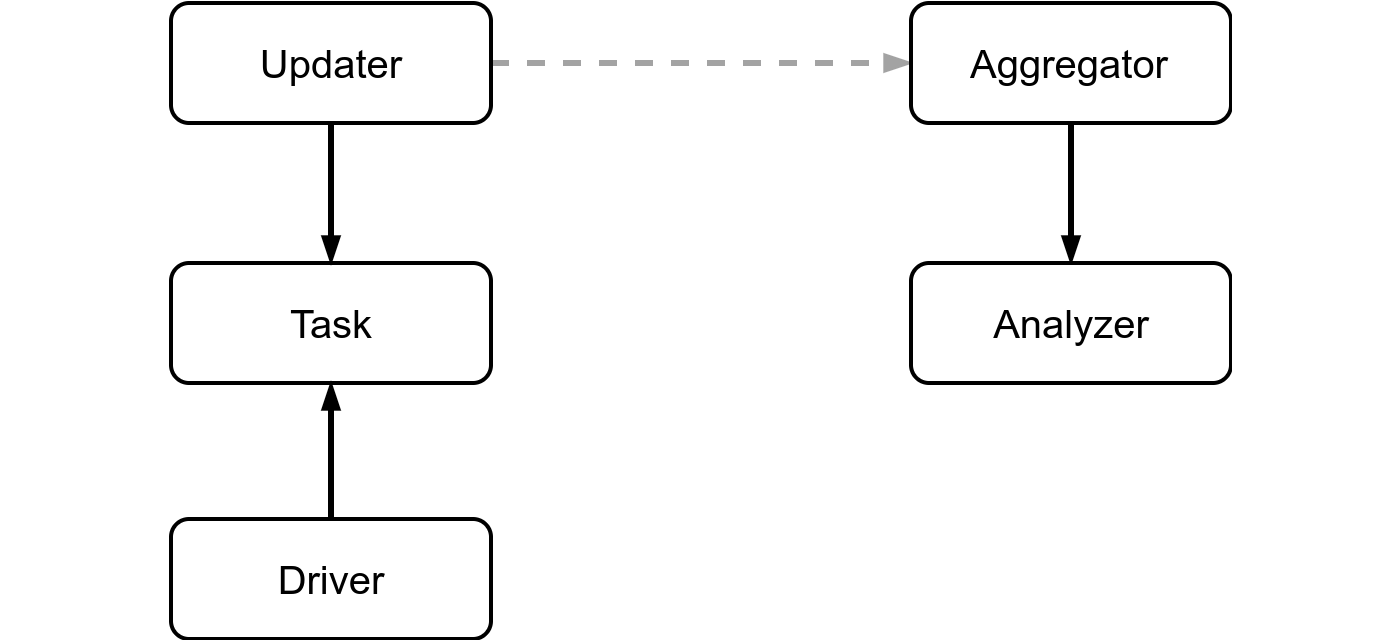
ROS diagnostics gives you the ability to monitor your system. There are two components in its architecture, the updater and the aggregator . The updater publishes diagnostic status messages on the /diagnostics topic, and the aggregator listens to these statuses, aggregates them, and publishes the results on the /diagnostics_agg topic.

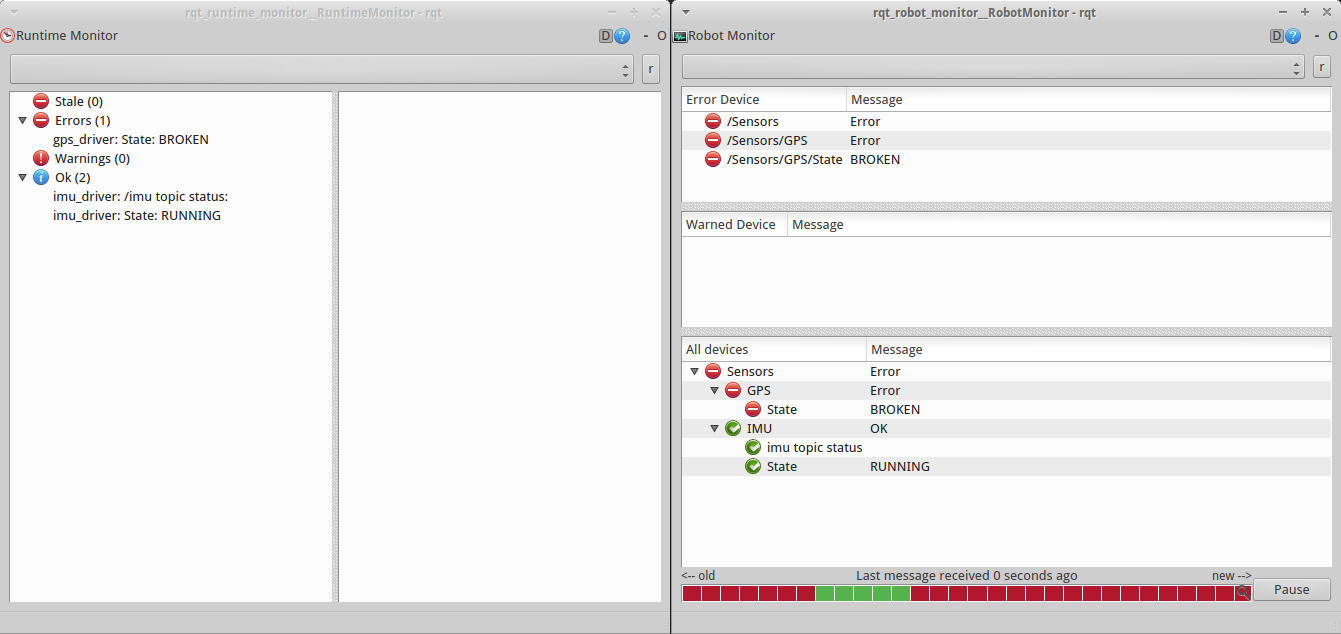
A system can have multiple updaters. They are meant to communicate with devices such as motors, sensors, computers, batteries, etc, in order to retrieve and publish relevant status data. The information being published on the /diagnostics topic is flat, there is no hierarchy. So, you can say that it’s not easy to monitor this data. Thus, this is where the aggregator comes into play. The aggregator collects, categorizes, and groups the statuses from all the system components. You can take a look at what is being published on the /diagnostics and /diagnostics_agg topics with the rqt_runtime_monitor and rqt_robot_monitor tools, respectively. In the figure below, for example, you can see on the left that there are two statuses from an IMU and one from a GPS. Then on the right, these are placed by the aggregator under the sensors category and the IMU statuses are also grouped together.
From the technical side, all of this is implemented through tasks and analyzers. A task is the interface between an updater and a device. A device pushes data into a task, and then an updater forwards a status message to the task and asks to populate it. Once the updater gets the status messages from all the tasks it manages, it publishes them to the /diagnostics topic. On the other side, the aggregator uses analyzers. The aggregator forwards each status message it receives to all of the analyzers it manages. When the name of a status message is matched with the criteria of an analyzer, the analyzer analyzes the message. When it’s time to publish to the /diagnostics_agg topic, the aggregator requests a report from each analyzer. This report is just a list of status messages, one for each status item that the analyzer is responsible for, and one for the parent level that summarizes the state of its children statuses. For example, in the figure above, there is an analyzer that gathers the 2 IMU statuses. The analyzer will report 3 status messages, two for the items under IMU, and one summary status for the IMU level. This way, if any of the IMU statuses are in error, the IMU will inherit these errors, and you’ll immediately know that there is a problem with the IMU without having to look inside.
So, this is what you get from the ROS diagnostics out of the box: publication of statuses and categorization of statuses for easy monitoring. Of course, diagnostics is not just about looking at statuses, but also reacting appropriately when certain conditions are met. We’ll see examples of how we can do that in the next post.